
朝のオフィスでExcelとPDFの山に囲まれ、同じ手順を繰り返す日々に疲れていませんか。データのばらつき・ミス・遅延が現場の常識のように感じられることも。生成AIは、下書き作成・データ整理・要約を人の判断と組み合わせ、作業を速く正確に進める力を引き出します。本記事では、現場ですぐ使える具体例と手順、導入時の注意点、倫理・セキュリティを守りつつROIを見える化する方法を、難しい用語を避けてやさしく解説します。AIを“拡張ツール”として活用して、部門を横断する協働と新しい意思決定の形を掴みましょう。
第1章:山積みの業務を生み出す静かな現場
第1章:山積みの業務を生み出す静かな現場 - 本文
第1章:山積みの業務を生み出す静かな現場
朝のオフィスは、雨音とプリンタの連続音だけが響く。新人の佐藤海斗はExcelの山、PDFの海原に囲まれ、契約書の要件確認、見積もりの数値照合、顧客データの手入力を同じ手順で繰り返していた。ミスが混入し、誰かの検証待ちで業務が止まり、ダッシュボードの数字は合っているはずなのに遅い――そんな「気づかれにくい停滞」が日常化している。
現場の痛みは感覚だけではない。手作業でのデータ移し替えやPDF読み取りは、時間の浪費と人的ミスを誘発する。例えば紙やPDFからのテキスト抽出に使うOCR(光学文字認識)は便利だが、レイアウトやフォーマットが変わると誤読が増え、結果として再確認や手直しが発生する。VBAやRPA(例:UiPath Autopilot)で自動化しても、例外処理や設計ミスで保守コストが膨らむことがある。
一方で「生成AI(LLM)」は下書き作成や要約、パターン抽出で現場負荷を下げる可能性を示す。Google Document AIやAzure AI Document Intelligenceは文書構造を理解してデータ化し、Layout AIやOCRと組み合わせれば取り込み精度が上がる。さらに、RAG(Retrieval-Augmented Generation:外部データを参照して応答を補強する手法)を活用すれば、最新の社内ルールや契約条項を踏まえた出力が得られる。
しかし道具だけでは解決しない。リーガルテックやデータガバナンスの観点で、機密情報の取り扱い・ログ管理・最終判断の責任所在を明確にする必要がある。海斗が手にした「生成AIで業務をハックする」という提案書は、ここから始まる現場再設計の羅針盤だ。次節では、具体的な適用例と初動で注意すべきポイントをやさしく示していく。
第2章:RAGと協働の誕生
第2章:RAGと協働の誕生 - 本文
第2章:RAGと協働の誕生
会議室で飛び交った言葉の背景には、単なるツールの導入以上の「構造的な問題」がある。現場で発生するミスや遅延は偶発的なものではなく、業務の設計とデータの扱い方に起因している。主な要因は次の通りだ。
-
データの非構造化と分散
企業内の情報の約80%は書類やPDF、メールなどの非構造データと言われる。これらは形式がバラバラで、OCRでも誤読が起きやすく、手動での正規化(形式そろえ)が必要になる。結果として検索や集計に時間がかかり、人的ミスを生む。 -
サイロ化した業務プロセス
営業・法務・人事・ITが別々のフォーマットやルールでデータを扱うと、横断的な意思決定が難しくなる。各部門に最適化された手順は、組織全体のボトルネックになりやすい。 -
検索・参照基盤の欠如
必要な情報を迅速に引き出せないと、最新版や根拠に基づく判断ができない。ここで有効なのがRAG(Retrieval‑Augmented Generation):外部や社内のドキュメントを検索(例:BM25やエンティティ拡張検索)して、最新情報を踏まえた下書きを生成する仕組みだ。BM25は文書の関連度を測る古典的な方法で、エンティティ拡張検索は固有名詞や属性を手がかりに精度を上げる。 -
ツールと人の役割分担が未整備
藤原が言う「ハイブリッドモデル」は、AIに下書きや要約を任せ、人間が最終判断をする設計だ。UiPath AutopilotやGoogle Document AI、Azure AI Document Intelligence、GPT系APIなどは強力だが、出力の検証プロセスやログ・責任所在を決めておかないとリスクが残る。
構造的原因の解消には、まず「データ整備」と「検索基盤の強化」、そして「小さなパイロットで検証→拡大」が有効だ。RAGを中心に据えつつ、プロンプト設計(プロンプトエンジニアリング)やOCR改善、ガバナンス(ログ・アクセス権・責任ルール)をセットで整えることが、現場の変化を安全かつ確実に導く鍵になる。
第3章:非構造データの構造化とリライト
第3章:非構造データの構造化とリライト - 本文
第3章:非構造データの構造化とリライト
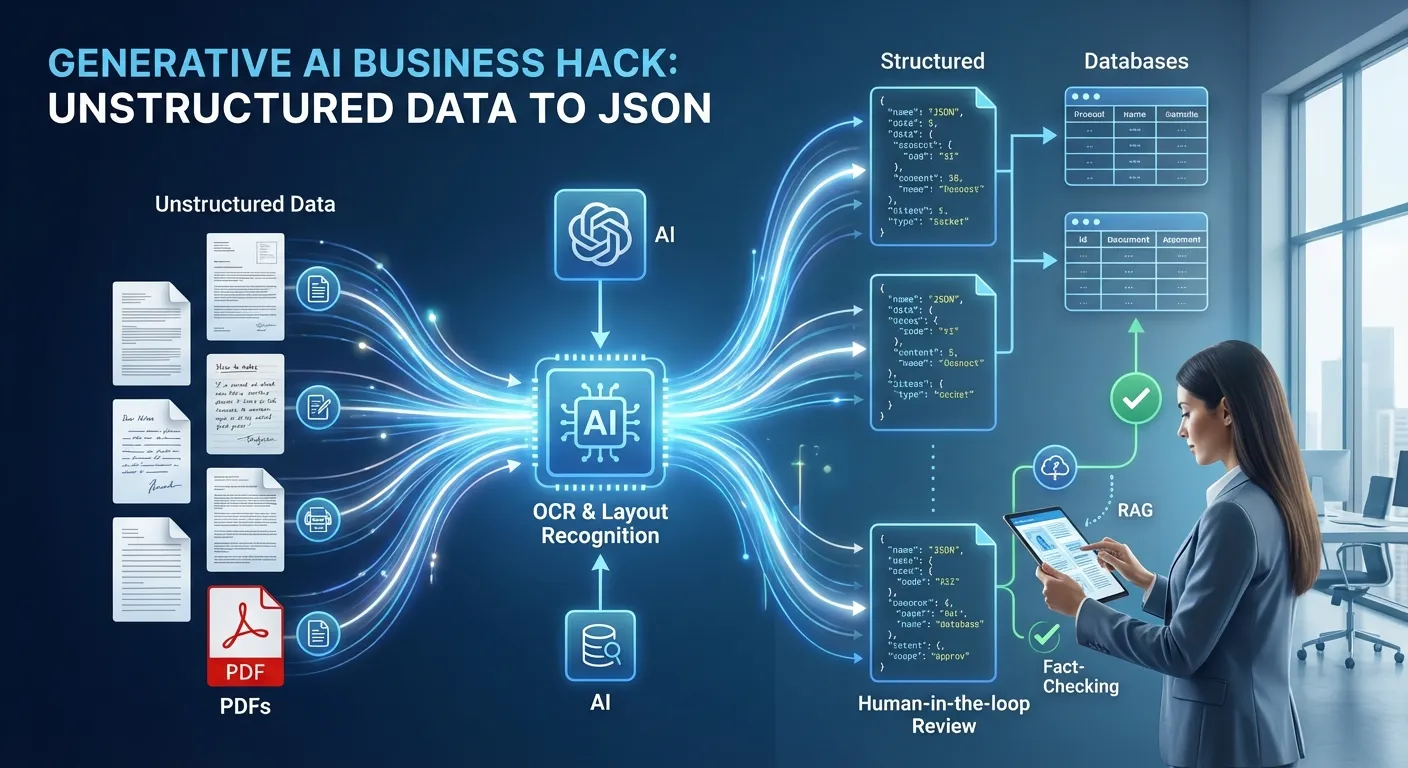
営業の見積・契約を対象にしたパイロットで見えたのは、「取り出せない情報」をどう安定してJSON化するか、という現場の本質課題です。海斗と美咲の流れを踏まえ、現場ですぐ使える複数のアプローチを示します。
OCR(光学式文字認識)
画像やPDFから文字を読み取り、テキスト化する技術。手書きや表は精度が下がることがある。
レイアウト認識 / Document AI
文書の表や項目の配置を解析し、項目ごとに取り出す機能。Google Document AIやAzure AI Document Intelligenceが代表例。
JSON(データ構造)
項目名と値をキーとバリューで表すフォーマット。システム連携や検索に適している。
RAG(Retrieval-Augmented Generation)
検索で取り出した文書を元にAIが下書きを生成し、人が検算・判断する運用モデル。
アプローチA:クラウドDocument AI中心(Google + Azure)
- メリット:高精度な表抽出とレイアウト解析、運用負荷が低い。複雑PDFに強い。
- デメリット:データの送信先やコスト管理が課題。個人情報や機密は要注意。
アプローチB:ハイブリッド(オンプレOCR + クラウド構造化)
- メリット:機密データを社内で保持しつつ、構造化はクラウドの強みを使える。コンプライアンスに強い。
- デメリット:導入の手間と運用の複雑さが増す。
アプローチC:人とAIの密な協働(Human-in-the-loop)
- メリット:精度を担保しやすく、現場の知見を反映しやすい。誤変換の早期発見が可能。
- デメリット:人手コストが残る。スケールには工夫が必要。
アプローチD:レガシーコードの現代化(Code LLMでVBA→モダンコード)
- メリット:既存ロジックを効率的に移植でき、保守性が向上する。
- デメリット:生成コードの検証が必須。LLMの出力はそのまま信頼しないこと。
現場での実行手順(推奨)
- 小さい範囲(見積・契約)でパイロット実施。
- OCR+レイアウトで項目抽出→JSON化。
- Code LLMでVBAロジックをリライト。
- RAGで下書きを生成し、人が検算・判断(Validation & MIS)。
- 結果をフィードバックしてモデルとパイプラインを改善。
最終的に重要なのは「AIが最適解を出す場」ではなく「人が判断しやすい下書きを出す場」を作ることです。未構造データをまず構造化する習慣が、現場の速度と精度を安定させます。
第4章:精度・セキュリティ・倫理の壁
第4章:精度・セキュリティ・倫理の壁 - 本文
第4章:精度・セキュリティ・倫理の壁(実装手順)
序文:幻覚(ハルシネーション)やデータ品質、法務・倫理リスクを現場で制御するための、実行可能なステップを示します。小さなパイロットから始め、検証→運用化→監査の順で進めましょう。
- 現状把握(1週)
- 取り扱うデータを分類(機密/準機密/公開)し、OCR→JSON化対象を選定。
- シャドーITや外部サービス利用の棚卸を行う。
- パイロット設計(2〜4週)
- 代表的サンプル100件でOCR→レイアウト抽出→JSON化→RAG下書きの流れを構築。
- 合格基準を設定(例:キー項目誤差率 < 5%、モデル信頼度 > 0.8)。
- 検証レイヤーを作る(常設)
- ルールベース検証(必須項目、形式チェック)+クロスソース照合(原本との突合)。
- 人間の「最終承認」ゲートを設ける(高リスク文書は複数承認)。
- セキュリティ実装(並行)
- 最小権限(Role-based Access)、暗号化(保存・転送)、監査ログを導入。
- ログはSIEMへ送付、改ざん防止のため保持期間と権限を明確化。
- 倫理・説明責任の仕組み(運用設計)
- 出力ごとに「ソース一覧」と「プロンプト」を記録し、説明可能性を担保。
- 人的責任の所在を明確にしたポリシーを作成。
- 監視と改善ループ(継続)
- 指標:精度、再作業率、検出された幻覚件数、インシデント数、ROI。
- モデル劣化や業務ルール変更を検知したら再学習・ルール見直し。
- 組織整備と教育
- プロンプト設計、RAG運用、AIエージェント監視の担当を明確化。
- 運用手順書と事故対応フローを現場で訓練。
定義ボックス
データガバナンス:データの品質・利用ルールと責任を定める仕組み。
RAG(Retrieval-Augmented Generation):外部情報を取り込んで生成を補強する手法。
ハルシネーション:AIが事実でない情報を出力する現象。
最後に:ROIだけでなく「リスクの可視化」をダッシュボード化して、意思決定者が常にバランスを取れる仕組みを作りましょう。AIは拡張ツール――最終責任は人にあります。
第5章:拡大とROI—組織全体へ波及する価値

第5章:拡大とROI—組織全体へ波及する価値 - 本文
第5章:拡大とROI—組織全体へ波及する価値
パイロットが成功し、海斗たちは他部門へ展開を始めた。業界の普及率は2023年の33%から現在65–71%へ拡大し、45.7%が週5日以上AIを使う時代へ。現場の実感は88.4%が「効率化・質の向上」を挙げ、営業・CRMではリード転換が最大50%、データ入力は約17%短縮。成功企業のROIは平均3.8倍、失敗は1.2倍で、差は「全社員の定着度」に起因することが分かった。
具体例:
- 営業:AIでリード情報を自動判別し、質の高い案件へ優先配分。結果、転換率が大幅改善。
- バックオフィス:UiPath Autopilotで帳票の読み取り→基幹系入力を自動化し、入力工数を約17%削減。
- ドキュメント:Gamma・Canva AIで提案資料を高速作成、Otter.aiで会議記録を自動要約し工数削減。
拡大手順(現場でもすぐ実行できる)
- 成功したパイロットをテンプレ化して他部門へ横展開する
- 利用ルールとデータ品質チェックをガバナンス化する(幻覚や誤出力対策)
- 教育をセットにし、週次で利用率と成果をモニタ(ROIダッシュボードで可視化)
- セキュリティと倫理の責任体制を明確化して運用する
海斗の組織は、ツール連携と定着施策でROIを3.8倍に引き上げた。重要なのは「部分最適で終わらせず、定着と監視で全社最適にすること」。まずは一部門での再現性確認から始め、数値で効果を示して次の投資決定を後押ししましょう。
第6章:人間とAIの新しい協働の形
第6章:人間とAIの新しい協働の形 - 本文
第6章:人間とAIの新しい協働の形
六ヶ月の取り組みで得た結論は明快です。生成AIは「下書き」を出すことで私たちの知的能力を拡張するパートナー。最終判断と創造性は人間が担い、プロンプトの磨き込みと出力の検証が成功を決めます。
重要ポイント:
プロンプトエンジニアリング:問い方を工夫し、再現性を高めるRAG(検索を組み合わせた回答):社内ドキュメントから正確に情報を引く仕組みLLM(大規模言語モデル):文章生成の中核。使い方と限界を理解する- 検証フロー:人が必ずチェックするルールを定着させる
- データ品質・倫理・セキュリティ:説明責任を担保する
Right to Disconnect:働きすぎを防ぐ境界設定
次の具体的アクション(短期→中期→長期):
- 30日:部門ごとに1作業を選定しテンプレ化。まずはA/Bで比較
- 90日:
LLM(大規模言語モデル)+RAGでナレッジ連携、精度指標を設定 - 180日:横展開と教育プログラムの常設化、監査と倫理レビューを実行
サンプルプロンプト(テンプレート):
目的:会議録を要約し、次アクションを抽出する
入力:<会議録テキスト>
出力:箇条書きで3件のアクション(担当候補付き)
検証基準:事実誤認0件、重要事項の網羅度90%以上
最後に:小さく始めて検証→改善→拡大を繰り返してください。AIは拡張ツールであり、最終的な価値は人間の判断と組織のルールで決まります。次の一手を今、具体化しましょう。
関連キーワード
著者について
鈴木信弘(SNAMO)
鈴木信弘(SNAMO)- 静岡県焼津市を拠点に活動する総経験19年のフルスタックエンジニア。AI時代の次世代検索最適化技術「レリバンスエンジニアリング」の先駆的実装者として、GEO(Generative Engine Optimization)最適化システムを開発。2024年12月からSNAMO Portfolioの開発を開始し、特に2025年6月〜9月にGEO技術を集中実装。12,000文字級AI記事自動生成システム、ベクトル検索、Fragment ID最適化を実現。製造業での7年間の社内SE経験を通じて、業務効率75%改善、検品作業完全デジタル化など、現場の課題を最新技術で解決する実装力を発揮。富山大学工学部卒、基本情報技術者保有。
プロフィールを見る