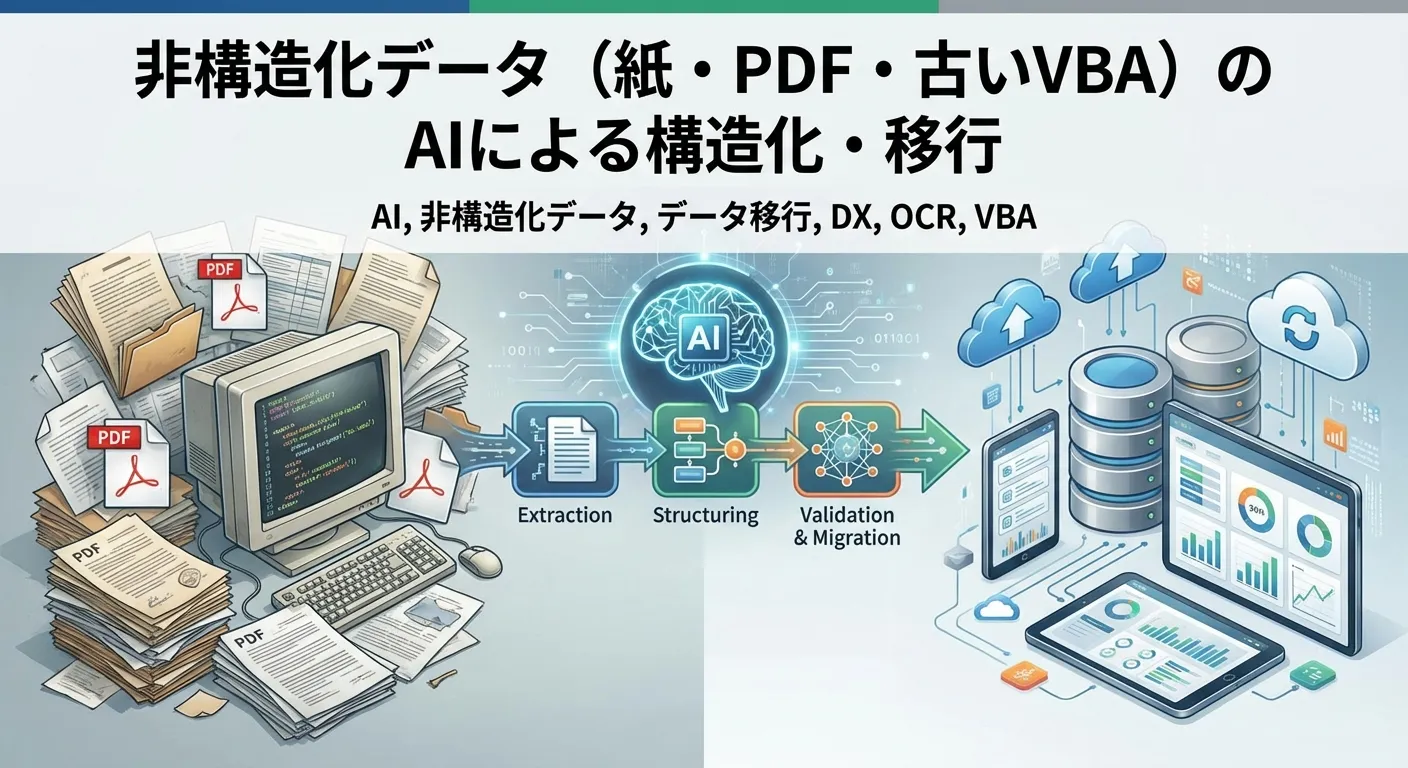
紙束とPDF、そして長年走るVBAが、社内データの眠れる資産として山積みになる現場は珍しくない。本記事は、AIを活用した Extraction*・Structuring*・Validation & Migration* の3段階で、読み取りだけでなく業務のルールまで整理し、データを新しい仕組みに安全に渡す道を示す。小さなサンプルで検証を重ね、誤りは人の目で補完する現実的な運用を軸に、セキュリティと品質を最優先する手順を解説。続く章では現場の実例と具体的な手順が一貫して紹介され、データが資産へと変わる未来像が描かれる。
第1章:紙と古いVBAが眠るデータの迷宮
第1章:紙と古いVBAが眠るデータの迷宮 - 本文
第1章:紙と古いVBAが眠るデータの迷宮
名取翔は、東京の中堅IT企業「NEXIAソリューションズ」のデータ基盤設計チームで働く若手エンジニアだ。社内には数十年分の紙資料とPDF、そして長年動き続けるVBA*マクロが山積みになっている。紙は手書きや様式違いで表の列や項目が統一されておらず、PDFはレイアウト崩れや文字化けで自動読み取りが難しい。VBAは依存関係が複雑で、どの処理がどのデータを生み、どの報告書に繋がるかを追うだけで一日が過ぎる。
現場の作業は「読み取り→手で整形→突合せ」の繰り返しで、業務ロジックは個人の経験に依存している。結果として、分析や自動化の足かせとなり、市場バスケット分析のような消費パターン解析も実施できない。過去のIoTセンサーやAIカメラを使った小規模なPoCでは、稼働率向上 15% といった成果や年間0件の突発停止といった指標が示されたが、これらを全社展開するためのデータ基盤整備は進んでいない。
翔は上司の言葉を思い出す。「非構造データのAIによる構造化は、Extraction → Structuring → Validation & Migrationの三段階で進めるべきだ」。まずは小さなPoVで抽出と検証を回し、誤りは人の目で補完する運用設計が現実的だ。紙やPDFからはOCRで文字を取り出し、表の関係や意味を人手で定義してJSONやDB*に渡す設計図が必要になる。古いVBAは、再利用可能な業務ロジックと破棄すべきレガシー部分に切り分けることで、移行のリスクを下げられる。
ここでの課題は明確だ。眠れる資産を確実に掘り起こし、形式を揃え、業務ルールを文書化してから新しい仕組みに渡すこと。以降の章では、翔が描いた「ストーリー設計図」に沿って、実務で使える手順とチェックポイントを具体例とともに示す。
用語説明(本文中の*は以下を参照)
- DX*: デジタル・トランスフォーメーション。業務やビジネスモデルをデジタル技術で変革すること。
- AI*: 人工知能。データから学習し判断や予測を行う技術の総称。
- PoC*: 概念検証。小規模で技術的実現性を試す試験。
- PoV*: 価値検証。実際の業務価値を評価する試験。
- IoTセンサー*: 物理環境のデータを取得する小型センサー機器。
- AIカメラ*: 画像解析機能を持つカメラ。映像から自動で情報を抽出する。
- 市場バスケット分析*: 購買データの組み合わせを分析し、関連性を探る手法。
- VBA*: Excelなどで使われる古い自動化スクリプト言語。
- OCR*: 画像やスキャンから文字を読み取る技術。
- JSON*: データを入れ子構造で表現する軽量な形式。
- DB*: データベース。構造化データを保存・検索する仕組み。
第2章:転機となる出会い—AI導入チームとの初対面
第2章:転機となる出会い—AI導入チームとの初対面 - 本文
第2章:転機となる出会い—AI導入チームとの初対面
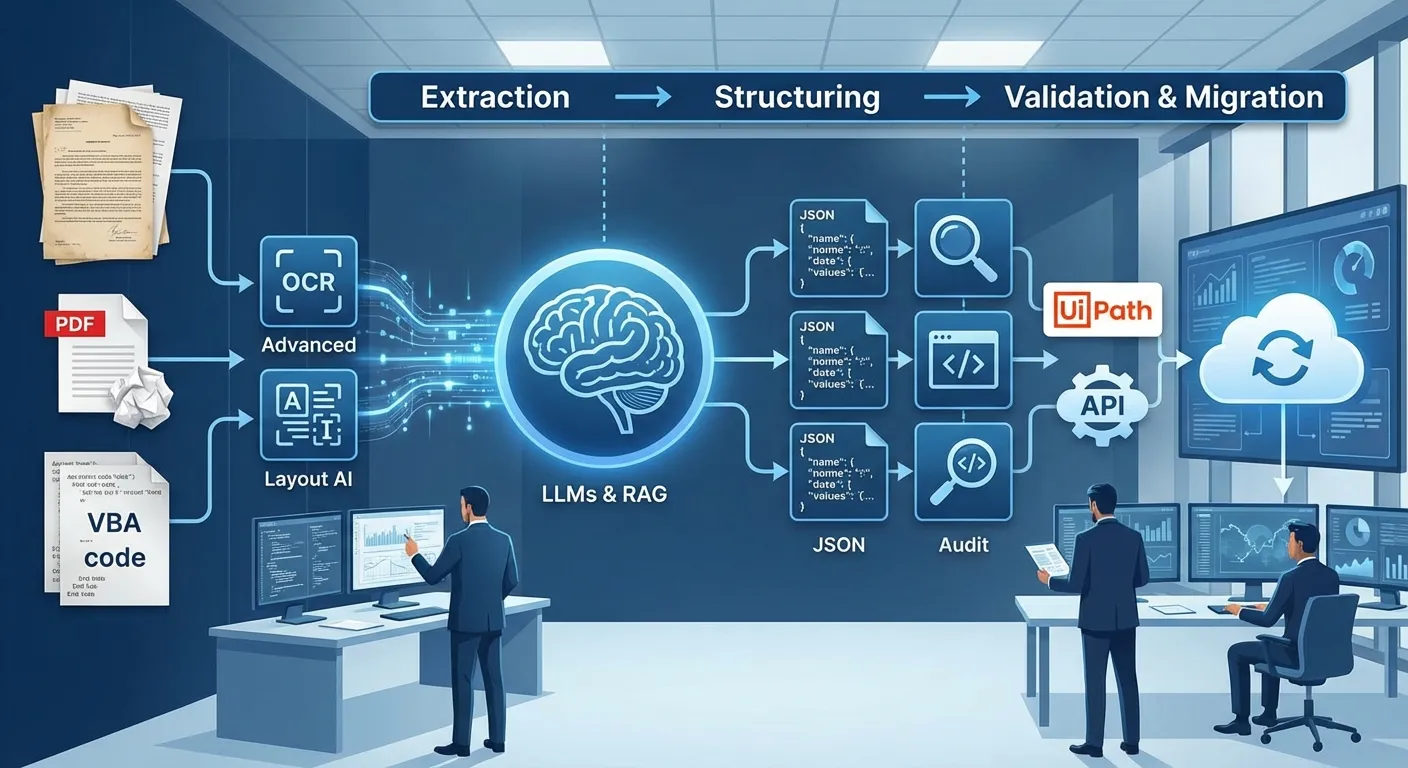
翔が初めて顔を合わせたのは、現場に寄り添う実践チームの奈美だった。奈美は一言で方針を示した。「まずExtraction、次にStructuring、最後にValidation & Migration」。紙はOCRとLayout AI、大きく崩れた帳票はGoogle Document AI*、複雑なPDFはAzure AI Document Intelligenceで読み、意味は文脈理解AI(LLM)で整理する。長年動くVBAはCode LLMで依存関係を解析し、現代の仕様に書き直す。読み取り後はJSONやCSVで渡し、UiPath Autopilotで入力や連携を自動化する──この道筋が示されたとき、翔は現場の問題の構造を理解し始めた。
なぜ問題が起きるのか。第一に、紙やPDF、VBAは長年の運用で各部署ごとに独自に蓄積され、統一されたルールやメタデータが欠けている。多くの調査で企業データの約80%が非構造化であり、フォーマットやレイアウトの多様性が自動化の障害になる。第二に、VBAなどのレガシー処理は「その場しのぎの改修」が繰り返され、依存関係と業務ロジックがブラックボックス化する。第三に、人手中心の運用は誤入力や仕様不整合を生み、データ品質が下がる。その結果、顧客クラスタリング、行動予測、離脱予測、需要予測、感情分析といった高度な分析が使えず、意思決定の遅れやコスト増を招く。
奈美の提案は構造的原因に直接応えるものだった。小さなサンプルでPoVを回し、AIで仕様書を先に作り、人の目で誤りを補う。こうして読み取り精度と業務ロジックの可視化を同時に進めれば、移行後の運用と品質も担保できると示した。翔のノートに残った方針は、以後の実践の核となる。
用語説明*
- OCR*: 画像上の文字を読み取ってデジタル文字にする技術。
- Layout AI*: 書類の見出しや表の位置を理解する技術。
- Google Document AI*: Googleの文書解析サービス。
- Azure AI Document Intelligence*: Microsoftの複雑文書解析サービス。
- LLM*: 大きな言語モデル。文脈を理解して文章を扱えるAI。
- Code LLM*: プログラムの解析や書き換えを支援する言語モデル。
- JSON*: データを項目と値で表す読みやすい形式。
- CSV*: 表形式をコンマで区切った簡易データ形式。
- UiPath Autopilot*: RPAツールの一部で、読み取りから操作まで自動化する仕組み。
第3章:構造化への実践—Extraction → Structuring → Validation & Migration
第3章:構造化への実践—Extraction → Structuring → Validation & Migration - 本文
第3章:構造化への実践—Extraction → Structuring → Validation & Migration
翔とチームは段階ごとに検証しながら進める方針を取った。Extractionでは紙をOCRで読み取り、Layout AIとLLMで表や項目を認識してJSON化する。StructuringではRAGを使い、Code LLMと人の監査でスキーマに合わせて整形する。Validation & MigrationではUiPath AutopilotやAPI*連携で新システムへ流し込む流れだ。
検討した具体的アプローチは三つある。
-
アプローチA(人中心・慎重型)
全ての抽出結果を人が細かく確認してから整形・移行する。メリットは精度と説明性が高く、規制や業務ルールが厳しい現場向き。デメリットは速度とコストがかかる。 -
アプローチB(AI先行・サンプリング検証型)
大量処理はAIに任せ、小さなサンプルを繰り返し検証してチューニングする。メリットはスピードと拡張性。デメリットは初期の誤認識が業務に影響するリスクがあるため監査設計が重要。 -
アプローチC(ハイブリッド・コード継承型)
VBA*の依存関係をCode LLMで解析・リライトし、UiPath Autopilotで移行パイプラインを自動化する。メリットは既存ロジックを維持しつつ自動化できる点。デメリットは技術的難易度と検証工数が大きい。
実務ではまず小さなPoV(検証)でBを試し、重要ロジックはCで置き換え、最終的にAの厳格チェックを組み合わせるハイブリッド運用が現実的だ。AIと人の役割を明確にし、逐次フィードバックを回すことで紙・PDF・VBAの非構造データを安全に資産化していく。
定義(用語説明)
OCR*: 文字を画像から読み取る技術。
LLM*: 大きな文章のパターンを学んだAI。
Layout AI*: 文書の配置や表を理解する技術。
JSON*: 構造化データの軽量な表現形式。
RAG*: 検索した情報をAIが統合して使う手法。
Code LLM*: プログラムコードの変換や解析を行うAI。
UiPath Autopilot*: 自動化ツールの一種(移行パイプラインに利用)。
API*: 異なるソフト同士をつなぐ仕組み。
VBA*: 古い社内処理で使われるマクロ言語。
Extraction*/Structuring*/Validation & Migration*: 本稿で使う三段階の工程名。
第4章:壁を越えるための現実の対策—ハルシネーションとセキュリティ
第4章:壁を越えるための現実の対策—ハルシネーションとセキュリティ - 本文
第4章:壁を越えるための現実の対策—ハルシネーションとセキュリティ
- 準備フェーズ(仕様書自動生成と隔離)
- 既存業務ルールをAIにより仕様書化(テンプレート出力→人の承認)。仕様書が移行と検証の基準になる。
- データ処理は必ずクローズド環境*で実行。ネットワーク分離、暗号保管、最小権限でアクセス制御を実装。
- 抽出・整形段階の例外設計
- AIの出力に信頼度閾値を設定。閾値未満は自動的に「要確認」フラグを付与。
- 連鎖的誤りを防ぐため段階ごとに小さなサンプル検証(A/Bテスト的にBを試しCに適用)。
- 人間検証と監査
- 承認ワークフローを組み込み、検証者は変更履歴と監査ログ*で差分を確認。
- 抽出ミスが見つかった場合は例外ルールを追加し、AIモデルのヒントとしてフィードバックする。
- 移行前の総合検証とロールバック計画
- ステージング環境で完全リハーサル。自動テストとサンプリング検査を併用し、復旧手順(MTTR)を明確化。
- 移行時はバッチ単位で切り替え、問題発生時は即時ロールバック。
- 古いVBAの再実装
- Code LLM*で依存関係を抽出し、ユニットテストと仕様に基づく段階的リライトを行う。人のコードレビューを必須化。
- 監視と運用
- API*アクセスは鍵管理・レート制御・異常検知で保護。定期的にログをレビューしKPI(MTBF/MTTR等)を監視。
定義(要点)
ハルシネーション*: AIが根拠なく誤情報を生成する現象。 クローズド環境*: 外部接続を遮断した安全な処理領域。 監査ログ*: 操作履歴や変更を記録する仕組み。 Code LLM*: コード解析・生成に特化した大規模言語モデル。 API*: 異なるソフトの連携用の窓口。
*用語説明は上記参照。
第5章:実践の成果—数字で語る移行の実力
第5章:実践の成果—数字で語る移行の実力 - 本文
第5章:実践の成果—数字で語る移行の実力
紙やPDF、古いVBAの資産を段階的にAIで読み取り・整理した現場では、具体的な成果が現れた。経理報告作成の工数は約50%削減、日常のデータ入力時間は約17%に短縮。営業・CRMでのリード転換は最大50%向上し、データ領域の自動化と標準化が品質を底上げした。導入普及率は2023年から65–71%へ拡大し、AIを日常的に使う人の45.7%が週5日以上利用している。成功企業のROIは約3.8倍、失敗例でも1.2倍と示唆される。UiPath Autopilotを核にした自動化では、データが正しく整い新システムへ安定投入されることで、業務は「待機・修正時間の削減→生産性向上」の好循環に入った。翔はチームに向けて、まず仕様をAIに作らせ業務ロジックを整理してから移行することが、DDDMとFinOps*を両立させる近道だと伝えた。この流れは、データを資産に変える実践モデルとして社内外に広がっている。
用語説明
UiPath Autopilot*:業務の繰り返し作業を自動化するソフトウェアの一種。
DDDM*:データに基づいて意思決定を行う手法。
FinOps*:費用対効果を意識してクラウドやIT投資を管理する運用方法。
第6章:学びと未来への設計図
第6章:学びと未来への設計図 - 本文
第6章:学びと未来への設計図—総括と次の一歩
非構造データのAIによる構造化・移行は単なる自動化ではなく、業務の標準化とデータ信頼性を高め、組織文化を変える取り組みである。重要な点を整理する。
- 仕様書を先に作る(
Extraction -> Structuring -> Validation & Migrationを業務視点で定義) - ハルシネーション対策は閉域+例外処理+人の検証で運用
- 小さなサンプルで検証し、段階的に拡張する
- DB/API連携と統合プラットフォームでエンドツーエンド化を目指す
- DDDMとFinOpsを両輪にしてROIを測る
次の具体的アクション例(すぐ実行できるチェックリスト):
1. 主要業務の仕様書を1件作成(KPI含む)
2. 代表的な紙/PDF/VBAを1セット選定
3. 小規模で`Extraction -> Structuring -> Validation & Migration`を実行
4. 結果を人が検証、改善ルールを追加
5. 自動化を段階的に拡張し、コストと品質を測定
最後に、データは資産として扱われるべきであり、正確な仕様と堅牢な検証プロセスが攻めのDXを支える。
用語説明:
DDDM*:データに基づく意思決定の仕組み。
FinOps*:クラウドコスト運用の手法。
API*:システム連携のための接点。
DB*:データを保存する仕組み。
UiPath Autopilot*:統合自動化プラットフォーム(例)。
関連キーワード
著者について
鈴木信弘(SNAMO)
鈴木信弘(SNAMO)- 静岡県焼津市を拠点に活動する総経験19年のフルスタックエンジニア。AI時代の次世代検索最適化技術「レリバンスエンジニアリング」の先駆的実装者として、GEO(Generative Engine Optimization)最適化システムを開発。2024年12月からSNAMO Portfolioの開発を開始し、特に2025年6月〜9月にGEO技術を集中実装。12,000文字級AI記事自動生成システム、ベクトル検索、Fragment ID最適化を実現。製造業での7年間の社内SE経験を通じて、業務効率75%改善、検品作業完全デジタル化など、現場の課題を最新技術で解決する実装力を発揮。富山大学工学部卒、基本情報技術者保有。
プロフィールを見る